From source to bytecode: a walk through CPython
python
internals
A high-level tour of how CPython turns a .py file into running code — tokenizer, PEG parser, AST, compiler, the eval loop — and the runtime underneath it: the GIL, memory, the garbage collector, and concurrency. Plus what changed in 3.13, 3.14, and 3.15.
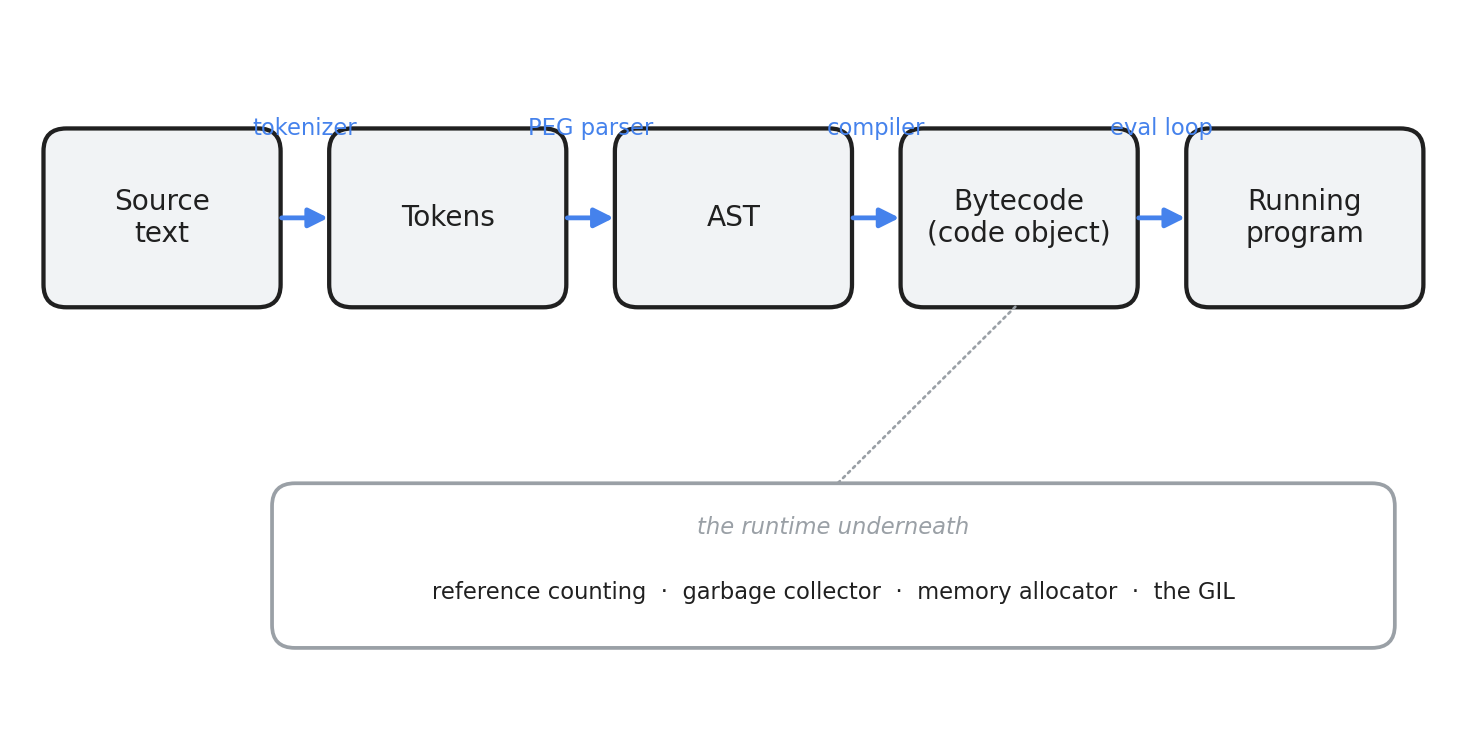
When you run python script.py, a lot happens before your first line of code does anything. CPython is the reference implementation of Python, written in C, and it puts your source through a small assembly line: text comes in one end, a stream of tokens forms, those tokens become a tree, the tree becomes bytecode, and a virtual machine runs the bytecode. Underneath all of that sits a runtime that manages memory, decides which thread gets to run, and cleans up after you.
This post walks that pipeline end to end. The goal is a map, not a manual. I keep each stage short, link to the official docs and the CPython source so you can dig in, and point out what changed in the recent releases (3.13, 3.14, and the in-development 3.15). Everything here runs on CPython 3.14, the current stable release.
Each box in that diagram is a stage with its own module you can poke at from Python itself. Let me take them in order.
Tokenizing: text becomes words
The first job is to chop the raw text into tokens — the smallest meaningful pieces. Names, numbers, string literals, operators, and the structural markers that make Python Python: newlines that end a logical line, and the INDENT/DEDENT tokens that stand in for the braces other languages use. CPython’s real tokenizer is written in C and lives under Parser/, but the standard library ships a pure-Python one you can run yourself, the tokenize module.
import tokenize, io
src = "x = 2 + 3 * 4\n"
for tok in tokenize.generate_tokens(io.StringIO(src).readline):
name = tokenize.tok_name[tok.type]
if name in ("ENCODING", "ENDMARKER", "NL"):
continue
print(f"{name:9} {tok.string!r}")NAME 'x'
OP '='
NUMBER '2'
OP '+'
NUMBER '3'
OP '*'
NUMBER '4'
NEWLINE '\n'Each token carries its type, its text, and its position in the source. The numeric values behind names like NAME and OP are generated from Grammar/Tokens and can shift between releases, so you always refer to them by name through the token module, never by number.
The tokenizer is where one of the more interesting recent reworks happened. Through Python 3.11 an f-string was handed to the parser as a single opaque STRING token, and a separate hand-written C routine picked it apart. That was fragile and full of special cases. PEP 701, in Python 3.12, formalized f-strings into the real grammar. The tokenizer now emits structured pieces — FSTRING_START, FSTRING_MIDDLE, FSTRING_END — and the parser handles the {...} expressions like any other code.
src = 'f"hi {name}"\n'
for tok in tokenize.generate_tokens(io.StringIO(src).readline):
n = tokenize.tok_name[tok.type]
if n in ("ENCODING", "ENDMARKER", "NEWLINE", "NL"):
continue
print(f"{n:14} {tok.string!r}")FSTRING_START 'f"'
FSTRING_MIDDLE 'hi '
OP '{'
NAME 'name'
OP '}'
FSTRING_END '"'The practical payoff: f-strings stopped having weird arbitrary limits. You can nest quotes of the same kind, use backslashes, and write multi-line expressions inside the braces. The lexer change is what made all of it fall out for free.
Parsing: words become a tree
A flat list of tokens has no structure. Parsing turns it into an abstract syntax tree (AST) — a nested representation where 2 + 3 * 4 knows that the multiplication binds tighter than the addition. Since Python 3.9, CPython uses a PEG parser (a parsing expression grammar) that replaced the old hand-maintained LL(1) parser; the old parser module was removed in 3.10. The grammar itself is a readable file, Grammar/python.gram, and the C parser is generated from it.
The key idea behind PEG is ordered choice. When a rule lists alternatives, they’re tried in written order and the first match wins. That removes the ambiguity that plagues older grammar styles, at the cost of needing memoization to stay fast (so-called packrat parsing). The full rationale is in the parser guide in the CPython internals docs.
You rarely touch the parser directly. You reach for the ast module, which gives you the tree as Python objects you can inspect, walk, or rewrite.
import ast
tree = ast.parse("x = 2 + 3 * 4")
print(ast.dump(tree, indent=2))Module(
body=[
Assign(
targets=[
Name(id='x', ctx=Store())],
value=BinOp(
left=Constant(value=2),
op=Add(),
right=BinOp(
left=Constant(value=3),
op=Mult(),
right=Constant(value=4))))])Read the nesting: the assignment’s value is a BinOp for +, whose right side is another BinOp for *. Precedence is baked into the shape of the tree, not decided later. This is the level tools like linters, formatters, and type checkers operate on, because it’s the first representation that actually understands the structure of your code.
Compiling: the tree becomes bytecode
The AST is still a description of your program, not something to execute. The compiler (Python/compile.c) lowers it into bytecode: a flat sequence of simple instructions for a stack machine. Along the way it builds a symbol table to work out which names are local, global, or captured from an enclosing scope, then turns the tree into a control-flow graph and emits instructions. The compiler design page in the developer guide walks the full path.
The result is a code object: bytecode plus everything needed to run it — constants, names, argument counts, line-number tables. The dis module disassembles it into something readable.
import dis
dis.dis(compile("x = 2 + 3 * 4", "<demo>", "exec")) 0 RESUME 0
1 LOAD_SMALL_INT 14
STORE_NAME 0 (x)
LOAD_CONST 1 (None)
RETURN_VALUETwo things to notice. First, there’s no 2, 3, 4, or any arithmetic in the output. The compiler folded the constant expression 2 + 3 * 4 down to 14 at compile time, so the running program just loads the answer. Second, LOAD_SMALL_INT is a specialized instruction for small integers — one of many narrow, fast opcodes CPython has grown over the years.
Disassembling a function shows more of that flavor:
def add(a, b):
return a + b
dis.dis(add) 1 RESUME 0
2 LOAD_FAST_BORROW_LOAD_FAST_BORROW 1 (a, b)
BINARY_OP 0 (+)
RETURN_VALUELOAD_FAST_BORROW_LOAD_FAST_BORROW is a single fused instruction that loads two local variables at once, and BINARY_OP is a generic operation the interpreter can later specialize once it sees what types actually flow through it. More on that in a moment.
One warning that the docs repeat and I’ll repeat too: bytecode is not stable. The instruction set changes every minor release, sometimes a lot. Never pickle it, never ship it between versions, never depend on a specific opcode existing. It’s an internal detail. dis is for understanding, not for building on.
The evaluation loop: running the bytecode
The bytecode finally runs in the evaluation loop, the heart of the interpreter, in Python/ceval.c. At its core is a function, _PyEval_EvalFrameDefault, that walks the instructions of a frame (one call’s worth of execution state — its locals, its value stack, its position in the bytecode) and does what each one says. Call a function and a new frame goes on the stack; return and it pops off.
For most of Python’s history this was a big dispatch loop: fetch an instruction, jump to the code for it, repeat. The last few releases have made it considerably cleverer, and that’s where a chunk of recent performance work lives.
The specializing adaptive interpreter (PEP 659, Python 3.11) is the big one. The interpreter watches which instructions run hot and rewrites them in place into specialized forms. A generic BINARY_OP that keeps seeing two integers quietly becomes an int-only add that skips the type checks. If the assumption later breaks — someone passes strings — it falls back to the general version. You write ordinary Python; the interpreter adapts the bytecode to your actual data as it runs.
The experimental JIT (PEP 744, Python 3.13) goes a step further. Hot code is translated into a lower-level sequence of micro-operations, optimized, and then compiled to actual machine code using a technique called copy-and-patch. It’s off by default and has to be built in explicitly, so it’s still a preview rather than something most people run. What’s new in 3.14 is that the official Windows and macOS installers now ship the experimental JIT in the binary, so it’s far easier to try — but it remains experimental.
The tail-call interpreter (Python 3.14) is a different, quieter speedup. Instead of one giant loop, each opcode becomes a small C function that hands control to the next via a guaranteed tail call, which lets the C compiler keep interpreter state in registers. It needs a recent Clang and is opt-in at build time, and it changes nothing you can observe from Python — same bytecode, same behavior, just a faster engine. (Worth a caution: the early headline numbers were inflated by a compiler regression in the baseline; the honest figure is a few percent.)
The runtime underneath
The pipeline above tells you how code gets executed. It doesn’t tell you how the engine keeps house: who’s allowed to run, where objects live, and when they get cleaned up. That’s the runtime, and it’s where three of the most-discussed pieces of CPython sit.
The GIL
The global interpreter lock is a single mutex that lets only one thread execute Python bytecode at a time. It exists because CPython’s memory management — reference counting, which we’ll get to — isn’t thread-safe on its own, and a single lock is a simple, fast way to keep it correct. The lock is released around blocking I/O, so threads waiting on the network or disk run fine in parallel. The cost lands on pure-Python CPU work: ten threads doing math share one core’s worth of interpreter, not ten.
For decades the usual advice was “use processes for CPU parallelism, threads for I/O.” That’s now changing, and it’s the headline story of the last two releases.
PEP 703 makes the GIL optional. It’s a separate build of CPython — the executable is named with a t suffix, like python3.14t — that removes the global lock and instead protects shared state with finer-grained mechanisms (biased reference counting, per-object locks, a different memory allocator). It arrived as experimental in 3.13. In 3.14 it became officially supported (PEP 779) — still a separate, opt-in build and not the default, but no longer a preview. The single-threaded cost has come down to roughly 5–10%, and the specializing interpreter now works in the free-threaded build too. You can check at runtime:
import sys, sysconfig
free_threaded = bool(sysconfig.get_config_var("Py_GIL_DISABLED"))
print("free-threaded build:", free_threaded)
print("GIL currently enabled:", sys._is_gil_enabled())free-threaded build: False
GIL currently enabled: TrueThis is the standard build, so the GIL is present and on. On a python3.14t build the first line would say True, and threads could run Python in genuine parallel. Even on a free-threaded build the GIL can be switched back on at runtime (via PYTHON_GIL or -X gil=1), and it re-enables itself if you import a C extension that hasn’t declared itself safe without it.
A related route to multiple cores is PEP 684 (Python 3.12): a per-interpreter GIL. Multiple subinterpreters can live in one process, each with its own lock, so they run in parallel without sharing the single global one. That’s the foundation for the subinterpreter concurrency model I’ll come back to.
Memory: reference counting first
Every Python object carries a count of how many references point at it. Bind it to a new name, put it in a list, pass it to a function — the count goes up. Drop one of those — it goes down. When the count hits zero, the object is freed immediately. This is the primary memory manager, and it’s why so much Python memory is reclaimed the instant it’s no longer used, with no pause.
import sys
data = ["a", "b", "c"]
print("refs to the list:", sys.getrefcount(data) - 1)
also = data
print("after a second name:", sys.getrefcount(data) - 1)refs to the list: 1
after a second name: 2(getrefcount itself holds a temporary reference while it runs, hence the - 1.)
Under reference counting sits the allocator. CPython doesn’t ask the operating system for memory one object at a time; that would be slow. A specialized allocator called pymalloc grabs memory in big arenas and hands out small slices for the many short-lived little objects a Python program churns through. The free-threaded build swaps in a different allocator (mimalloc) suited to many threads allocating at once.
One detail that quietly enables a lot of the above: immortal objects (PEP 683, Python 3.12). A handful of objects that live for the entire program — None, True, False, small integers, interned strings — have their reference count pinned so it’s never touched. That avoids constantly writing to their counts, which matters for shared memory in pre-fork servers and for making the per-interpreter and free-threaded work tractable.
The garbage collector: cleaning up cycles
Reference counting has one blind spot: cycles. If a refers to b and b refers back to a, their counts never reach zero even after you drop every outside reference. That’s what the gc module is for. It’s a secondary collector that exists only to find and break reference cycles; everything else is handled by counting. The mechanics are written up in the garbage collector internals doc.
import gc
gc.collect() # start from a clean slate
a = {}
b = {}
a["b"] = b # a -> b
b["a"] = a # b -> a, a cycle
del a, b # outside references gone; refcounts still nonzero
unreachable = gc.collect() # find and free the cycle
print("objects reclaimed by the cyclic collector:", unreachable)objects reclaimed by the cyclic collector: 2Those two dicts couldn’t be freed by counting alone. The cyclic collector found them unreachable and reclaimed them. Classically it’s generational: new objects are checked often, survivors get promoted to older generations that are scanned less. The thresholds are tunable, and the default first-generation trigger was relaxed in 3.13 to collect less aggressively:
print("gc thresholds (gen0, gen1, gen2):", gc.get_threshold())gc thresholds (gen0, gen1, gen2): (2000, 10, 10)The collector’s exact strategy has been an area of active churn. The team has experimented with an incremental design that spreads each collection out to avoid long pauses, and walked it back more than once when it caused memory-pressure regressions in real workloads. The headline for someone writing Python: cycles are collected automatically, the policy keeps getting tuned, and the conceptual model (counting does the bulk, the cyclic GC mops up cycles) is stable even as the internals move.
So where do memory leaks come from?
With all this, “leak” in Python rarely means the C sense of orphaned memory. It usually means objects that are still reachable, so neither mechanism is allowed to free them. The usual suspects:
- A long-lived container (a module-level list, a cache dict) you keep appending to and never trim. Everything in it is alive by definition.
- A cache without eviction — the most common one in practice.
functools.lru_cachewith a bound, or aweakref-based structure, fixes it. - Objects that define
__del__and sit in a cycle, which historically could stall collection (much improved in modern versions). - A C extension that miscounts references — the one place a true low-level leak can still creep in.
The tools to chase these live in the standard library: tracemalloc to see where allocations come from, gc.get_objects() and gc.get_referrers() to ask what’s keeping something alive, and sys.getrefcount for a quick check.
Branching out: the concurrency models
Once you understand the GIL, the menu of concurrency tools makes sense. Each one is a different answer to “how do I do more than one thing, given that lock?”
Threads (threading) are real OS threads, but on the standard build the GIL means only one runs Python at a time. Perfect for I/O-bound work, where threads spend their time waiting and the lock is free. Not a path to multi-core CPU speed — unless you’re on the free-threaded build, which is exactly the wall PEP 703 is tearing down.
Processes (multiprocessing) sidestep the GIL by running separate Python interpreters in separate processes, each with its own lock and memory. True parallelism, at the cost of no shared memory by default and the overhead of pickling data across the boundary. A safety-relevant change landed in 3.14: on most Unix systems the default start method moved from fork to forkserver, because fork in a multi-threaded program is a long-standing source of deadlocks. If you relied on fork, you now request it explicitly.
Async (asyncio) is single-threaded concurrency. One thread, one event loop, many coroutines that voluntarily yield at await points. No GIL contention because there’s only one thread; the win is handling thousands of mostly-waiting connections without thread overhead. It’s cooperative, so one coroutine that blocks on CPU work stalls everything — the model is for I/O, not computation.
Subinterpreters (PEP 734) are the newest branch, and they sit between threads and processes. Built on the per-interpreter GIL, multiple isolated interpreters run inside one process, each with its own lock, so they execute Python in parallel — but with far less isolation cost than separate processes. Python 3.14 exposed them to Python code for the first time, through the new concurrent.interpreters module, plus an InterpreterPoolExecutor in concurrent.futures that runs each worker in its own interpreter.
The rule of thumb, slightly rewritten for 2026:
- I/O-bound, many connections →
asyncio - I/O-bound, simpler or blocking-library code → threads
- CPU-bound → processes, or subinterpreters, or the free-threaded build if you can use it
import os
# A neutral way to size a thread/process pool to the machine.
print("CPUs available to this process:", os.process_cpu_count())CPUs available to this process: 6What’s new, gathered up
The recent releases touch almost every stage above. Pulling the thread together:
Python 3.13 was the foundation release for the big shifts. Experimental free-threading (PEP 703) and the experimental JIT (PEP 744) both landed as previews. It also shipped a much nicer REPL — multiline editing, colors, paste handling — borrowed from PyPy, and gave locals() well-defined behavior in PEP 667.
Python 3.14 (released October 2025) is where several of those grew up. Free-threading became officially supported, subinterpreters got a real stdlib API, and the JIT started shipping in the official installers. On the language side it added two features worth knowing:
Deferred annotations (PEP 649) changed how type hints are stored. Annotations are no longer evaluated when a function or class is defined; they’re computed lazily on demand, so forward references just work without quoting them in strings. A new annotationlib module gives you control over how you read them back.
Template strings (PEP 750), or t-strings, are a new sibling of f-strings. A t"..." doesn’t produce a finished string — it produces a Template object that keeps the literal parts and the interpolated values separate, so a library can process them safely before assembling the result. It’s built for the exact situations where f-strings are dangerous: SQL, shell commands, HTML.
from string.templatelib import Template, Interpolation
name = "world"
template = t"hello {name}"
print("type:", type(template).__name__)
for part in template:
if isinstance(part, Interpolation):
print(f" interpolation: expr={part.expression!r} value={part.value!r}")
else:
print(f" literal text: {part!r}")type: Template
literal text: 'hello '
interpolation: expr='name' value='world'The static text and the substituted value stay distinct, which is what lets a template-aware function escape the value correctly instead of trusting an already-flattened string. 3.14 also added Zstandard compression (compression.zstd) and a remote debugging hook that lets you attach pdb to a running process by PID.
Python 3.15 is in development — feature-frozen and in beta as of this writing, with a release planned for October 2026, so treat all of this as tentative until it ships. The draft what’s-new points at some genuinely interesting items: lazy imports (PEP 810) via a lazy import form that defers loading a module until first use, UTF-8 as the default text encoding regardless of locale (PEP 686), and a new profiling package including a low-overhead statistical sampling profiler. The free-threading and JIT work continues underneath. I’ll write these up properly once 3.15 is final and the list stops moving.
The shape of it
Step back and the whole thing is one straight line with a support structure beneath it. Text becomes tokens, tokens become a tree, the tree becomes bytecode, and a loop runs the bytecode — and under that loop, reference counting and a cyclic collector manage memory while the GIL (or its absence) decides who runs. Every stage is inspectable from Python itself: tokenize, ast, dis, gc, sys. That openness is the nicest thing about CPython. You don’t have to take the pipeline on faith; you can print it out and watch it work.
If you want to go deeper, the two best maps are the Python Developer’s Guide and the InternalDocs/ folder in the CPython source. Both are written for people seeing this for the first time, and both are kept current with the code.