asyncio, and how to actually schedule tasks with dependencies
python
asyncio
concurrency
What asyncio is and how it works underneath — coroutines, the send protocol, the event loop, futures and tasks. Then a concrete problem: running a graph of tasks where some wait on others. Three hand-rolled solutions, where each breaks, and the standard-library answer real engineers reach for: graphlib.TopologicalSorter driving an asyncio.TaskGroup.
A while back I walked through CPython’s internals and got as far as the concurrency models — threads, processes, async, subinterpreters — without saying much about how any of them work. This post zooms in on one: asyncio. I want to do two things. First, take it apart far enough that the magic word await stops being magic. Then use it to solve a problem that comes up constantly in real systems: you have a pile of tasks, some of them depend on others finishing first, and you want to run them as fast as the dependencies allow.
That second half started with a file a friend sent me. They had written three different ways to schedule tasks with dependencies in asyncio and asked which one was right. All three work. But “works on four tasks” and “correct in production” are different bars, and the gap between them is exactly the interesting part. Everything here runs on CPython 3.14.
Hold that picture. We will earn it by the end. First, the engine.
What asyncio actually is
The one-line version from the last post: async is single-threaded concurrency. One thread, one event loop, many coroutines that voluntarily hand control back at await points. There is no GIL contention because there is only one thread doing the work. The win is handling thousands of mostly-waiting things — open sockets, in-flight HTTP requests, database queries — without paying for a thread each.
The word that matters is cooperative. Threads are preemptive: the OS can yank the CPU away from one thread mid-statement and hand it to another, whenever it likes. Coroutines are the opposite. A coroutine runs until it decides to pause, by reaching an await, and only then can anything else run. Nothing interrupts it. That is the whole bargain — and it is also the trap. A coroutine that does heavy CPU work, or calls a slow blocking library, never reaches an await, so it freezes the entire loop. Async is for waiting, not for computing.
Coroutines, and the send protocol underneath
An async def function is a coroutine function. Calling it doesn’t run anything; it builds a coroutine object, the way calling a generator function builds a generator instead of executing the body.
import asyncio
async def greet(name):
await asyncio.sleep(0)
return f"hello {name}"
coro = greet("world")
print(type(coro).__name__)
coro.close() # we made one without running it; clean it upcoroutineSo how does it run? A coroutine is driven from the outside, one step at a time, by .send(). Every await deep inside it eventually bottoms out at a plain yield that surfaces a value to whoever is driving — and .send(x) resumes the coroutine, making that yield evaluate to x. That is the entire protocol the event loop speaks. We can play the loop’s part by hand with a low-level coroutine that yields:
import types
@types.coroutine
def yields(value):
received = yield value # surfaces `value` to the driver; resumes here on .send()
return received
async def child():
got = await yields("paused: I need this awaited")
return f"child resumed with {got!r}"
async def parent():
return await child()
c = parent()
first = c.send(None) # prime it: run until the first yield
print("driver sees:", first)
try:
c.send("here you go") # resume; value lands at the yield
except StopIteration as stop:
print("coroutine returned:", stop.value)driver sees: paused: I need this awaited
coroutine returned: child resumed with 'here you go'Read that carefully, because it is the load-bearing idea. await child() doesn’t call child like a function. It delegates to it — child’s yields pass straight up through parent to the driver, and the driver’s sends pass straight back down. await is, mechanically, “yield from this until it’s done.” The value a coroutine yields is its way of telling the loop “I’m parked on something; don’t resume me until it’s ready.” And a coroutine returning is just StopIteration carrying the return value, exactly like a generator. The event loop is the thing on the other end of send, doing this for thousands of coroutines at once. Nothing more mystical than that.
The event loop
The event loop is the scheduler. Strip it to its core and it is a while loop: take the coroutines that are ready to make progress, .send(None) into each until it parks on an await, collect what they’re waiting on, then ask the operating system “wake me when any of these file descriptors or timers is ready.” That last step is the whole point — the loop hands the waiting to the OS (via selectors, wrapping epoll/kqueue/IOCP) and sleeps. The kernel does the watching. When a socket has data, the loop wakes, resumes the coroutines that were parked on it, and goes around again.
You rarely touch the loop directly. asyncio.run() creates one, runs your coroutine until it completes, and tidies up:
async def main():
loop = asyncio.get_running_loop()
return type(loop).__name__
print(asyncio.run(main()))_UnixSelectorEventLoopThe modern advice (since 3.10ish) is to let asyncio.run own the loop and use asyncio.get_running_loop() when you need a handle from inside. Creating and managing loops by hand is a legacy pattern that mostly causes the “bound to a different loop” bug we’ll hit later.
Futures and tasks: the loop’s two handles
Two objects show up everywhere once you go past a single coroutine.
A Future is a placeholder for a result that isn’t ready yet. It has a state — pending, then either done with a value or done with an exception — and you can await it. Awaiting a pending future parks the current coroutine; calling future.set_result(x) later wakes it. It is the low-level “I promise a value eventually” primitive, and almost everything else is built on it.
A Task is a Future that wraps a coroutine and drives it. This is the crucial distinction. A bare coroutine does nothing until something sends into it. asyncio.create_task(coro) hands the coroutine to the loop and says “drive this to completion in the background, alongside whatever else is running.” That is how you get concurrency: not by awaiting coroutines one after another (that’s just sequential code with extra syntax), but by turning them into tasks the loop interleaves.
async def slow(label, secs):
await asyncio.sleep(secs)
return label
async def main():
# create_task schedules them concurrently; they overlap.
a = asyncio.create_task(slow("a", 0.2))
b = asyncio.create_task(slow("b", 0.2))
return await a, await b
print(asyncio.run(main()))('a', 'b')Both sleeps overlap, so that returns in about 0.2s, not 0.4. The mental model: create_task is “start it now and let it run,” await is “block here until this particular thing is done.” Keep them separate in your head and most asyncio confusion dissolves.
One footgun worth stating once: the loop only holds a weak reference to a task. If you call create_task and don’t keep the returned object anywhere, it can be garbage-collected mid-flight and silently vanish. The docs say so explicitly — keep a reference, or use a TaskGroup, which we’ll get to.
The problem: tasks with dependencies
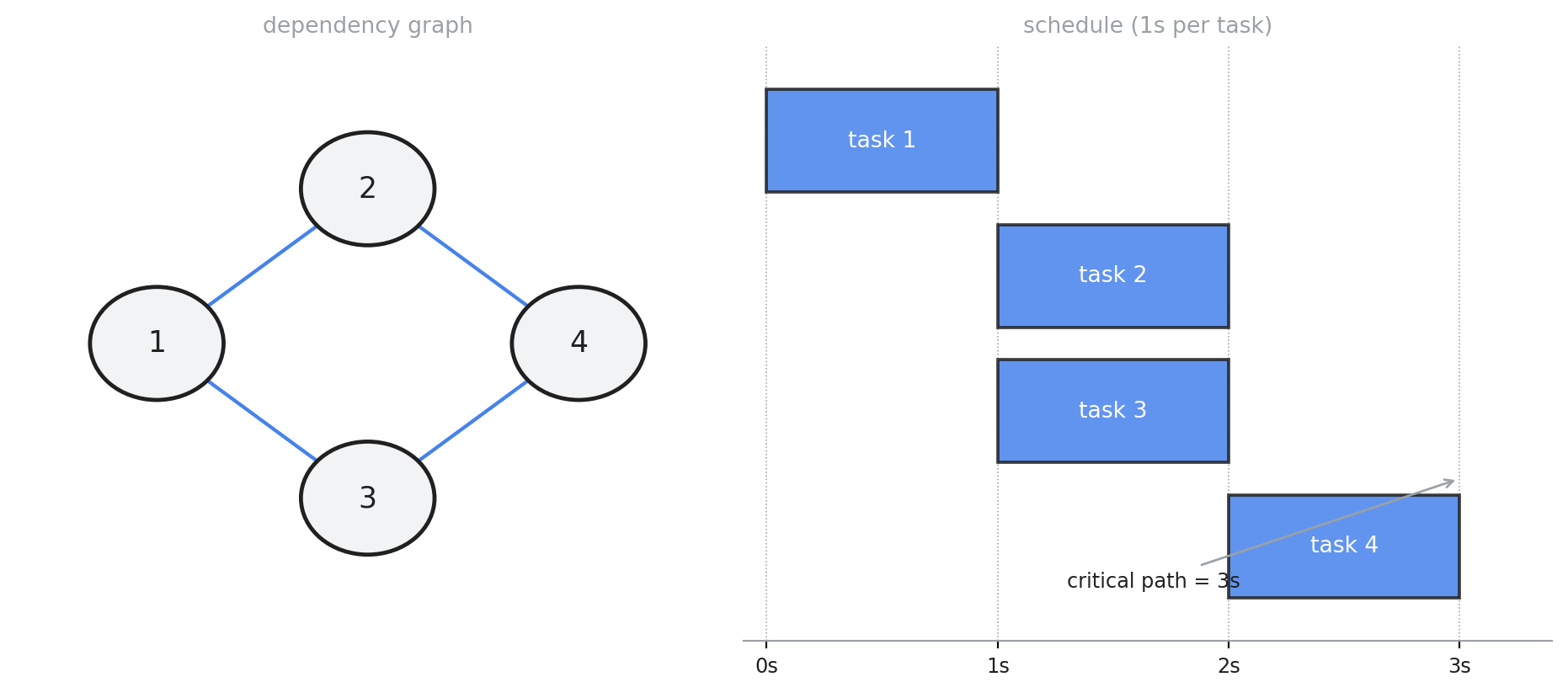
Here is the concrete thing. You have a set of tasks. Some can’t start until others finish. The textbook example, and the one my friend’s file used:
tasks = {
1: set(), # no dependencies
2: {1}, # waits for 1
3: {1}, # waits for 1
4: {2, 3}, # waits for both 2 and 3
}This is a directed acyclic graph (DAG): nodes are tasks, edges are “must finish before.” The goal is to run it as fast as the graph allows — start everything the moment its dependencies are met, overlap whatever can overlap. If each task takes one second, the floor is three seconds: 1, then 2 and 3 together, then 4. That is the critical path, and it’s the schedule in the figure up top. A correct scheduler hits it. We’ll time each approach against that three-second target, with a tiny stand-in for real work:
import time
async def handle(task):
print(f" task {task} starting at {time.perf_counter() - t0:.2f}s")
await asyncio.sleep(1) # pretend this is real I/O
print(f" task {task} done at {time.perf_counter() - t0:.2f}s")My friend wrote three solutions. Let me take them in order, run each, and find where each one breaks.
Approach 1: one Event per task
The cleanest of the three. Give every task an asyncio.Event — a one-shot flag a coroutine can await until someone flips it. A task waits on its dependencies’ events, does its work, then sets its own. asyncio.gather launches all of them at once and lets the events sort out the ordering.
async def run_with_events(tasks):
events = {task: asyncio.Event() for task in tasks}
async def handle_event(task):
# park until every dependency has set its event
await asyncio.gather(*(events[d].wait() for d in tasks[task]))
await handle(task)
events[task].set() # release anyone waiting on me
await asyncio.gather(*(handle_event(task) for task in tasks))
t0 = time.perf_counter()
asyncio.run(run_with_events(tasks))
print(f"events: {time.perf_counter() - t0:.2f}s") task 1 starting at 0.00s
task 1 done at 1.00s
task 2 starting at 1.01s
task 3 starting at 1.01s
task 2 done at 2.01s
task 3 done at 2.01s
task 4 starting at 2.01s
task 4 done at 3.01s
events: 3.01sThree seconds, dead on the critical path. Task 1 sets its event, tasks 2 and 3 both wake and run together, task 4 waits for both. All four coroutines launch at once and each blocks on exactly the right flags. It reads well and it is genuinely correct for this graph.
There is one thing to flag, because it bites people. In the original file the events dict was built at module level, before asyncio.run:
events = {task: asyncio.Event() for task in tasks} # at import timeThat looks harmless and on 3.14 it even runs — Event.__init__ stores no loop reference; it just sets up an empty waiter deque. Binding to a loop is lazy. The synchronization primitives inherit from a small internal _LoopBoundMixin, and the first time a primitive actually needs the loop it grabs the running one and pins itself to it:
import inspect
from asyncio import mixins
print(inspect.getsource(mixins._LoopBoundMixin._get_loop)) def _get_loop(self):
loop = events._get_running_loop()
if self._loop is None:
with _global_lock:
if self._loop is None:
self._loop = loop
if loop is not self._loop:
raise RuntimeError(f'{self!r} is bound to a different event loop')
return loop
So a module-level Event is fine as long as it is only ever touched inside one asyncio.run. Touch it from a second one and you get a crash. The binding only actually happens when a primitive has to wait — _get_loop() is called on the path that creates the waiting future, not on an uncontended fast path — so to see it we wait on an Event that’s never set (with a short timeout to escape the first loop):
shared = asyncio.Event() # built before any loop exists
async def touch():
try: # wait() on an unset Event calls
await asyncio.wait_for( # _get_loop() before it parks
shared.wait(), timeout=0.01)
except TimeoutError:
pass
asyncio.run(touch()) # loop A — `shared` pins to it
try:
asyncio.run(touch()) # loop B — fresh loop, different identity
except RuntimeError as err:
print("RuntimeError:", err)RuntimeError: <asyncio.locks.Event object at 0x111441d60 [unset]> is bound to a different event loopasyncio.run makes a brand-new event loop every call, and the primitive is still pinned to the dead one from the first run. The fix is simple: construct your events inside the coroutine that uses them, as run_with_events does above, not at import time. Same lesson as the event loop section — let asyncio.run own the loop and create loop-bound objects within it.
Approach 3: recursion with memoized tasks
The third version is the most ambitious and the most interesting to pick apart. Instead of pre-declaring a flag per task, it works recursively: to run a task, first run its dependencies, then run it. The catch with naive recursion is that task 4 depends on 2 and 3, both of which depend on 1 — so a plain recurse would run task 1 twice. The fix is memoization: cache the task object the first time you create it, hand back the same one on every later request. Two locks guard the shared dicts.
async def run_with_memo(tasks):
results, results_lock = {}, asyncio.Lock()
in_flight, create_lock = {}, asyncio.Lock()
async def run_task(task):
async with results_lock:
if task in results:
return
deps = [execute(d) for d in tasks.get(task, set())]
if deps:
await asyncio.gather(*deps) # wait for all dependencies
await handle(task)
async with results_lock:
results[task] = True
async def execute(task):
async with results_lock:
if task in results:
return
async with create_lock:
t = in_flight.get(task)
if t is None: # first request: create once
t = asyncio.create_task(run_task(task))
in_flight[task] = t
await t # everyone awaits the same task
await asyncio.gather(*(execute(task) for task in tasks))
t0 = time.perf_counter()
asyncio.run(run_with_memo(tasks))
print(f"memoized: {time.perf_counter() - t0:.2f}s") task 1 starting at 0.00s
task 1 done at 1.01s
task 2 starting at 1.01s
task 3 starting at 1.01s
task 2 done at 2.01s
task 3 done at 2.01s
task 4 starting at 2.01s
task 4 done at 3.01s
memoized: 3.01sThree seconds. It’s correct, and the core idea — memoize the task so shared dependencies run once — is exactly right. The in_flight dict mapping each task to its single Task object, with everyone awaiting the same one, is a genuinely good pattern. You’ll see it in dataloaders and request-coalescing caches.
But the two locks deserve a hard look, because this is where “works” and “correct under concurrency” pull apart. The thing to understand: in asyncio, code between two awaits runs atomically. There is no preemption. A coroutine cannot be interrupted except at an await point. So the question for any lock is always “does the critical section contain an await?”
Look at results_lock. Its critical section is if task in results: return — a dict membership test, no await inside. On a single-threaded event loop that’s already atomic; the lock guards nothing. It’s a no-op that adds two acquire/release round-trips.
create_lock is subtler and almost matters. Its critical section — check in_flight, and if absent create the task and store it — is the check-then-act you’d absolutely need a lock for under real threads. But again: is there an await between the check and the store? No. asyncio.create_task schedules the coroutine but doesn’t yield to the loop — it returns immediately, synchronously. So the check-and-store is already atomic on the event loop, and the lock, once more, guards nothing.
This is the single most common misconception when people come to asyncio from threads. You reach for a Lock out of habit, but asyncio.Lock is not for protecting data from concurrent access — single-threaded cooperative scheduling already does that for any critical section without an await. It exists for the opposite case: when you do await something in the middle of a critical section (an HTTP call, a DB write) and need to stop other coroutines from entering that same section while you’re parked. No await in the section, no need for the lock. Both locks here can come out and the program is identical:
async def run_with_memo_nolocks(tasks):
in_flight = {}
async def run_task(task):
deps = [execute(d) for d in tasks.get(task, set())]
if deps:
await asyncio.gather(*deps)
await handle(task)
def execute(task):
if task not in in_flight: # atomic: no await before the store
in_flight[task] = asyncio.create_task(run_task(task))
return in_flight[task]
await asyncio.gather(*(execute(task) for task in tasks))
t0 = time.perf_counter()
asyncio.run(run_with_memo_nolocks(tasks))
print(f"memoized, no locks: {time.perf_counter() - t0:.2f}s") task 1 starting at 0.00s
task 1 done at 1.00s
task 2 starting at 1.00s
task 3 starting at 1.00s
task 2 done at 2.00s
task 3 done at 2.00s
task 4 starting at 2.00s
task 4 done at 3.00s
memoized, no locks: 3.01sSame three seconds, half the code, and execute doesn’t even need to be async anymore — it’s a plain memoizing factory that returns a task to await. The recursion-with-memoization idea was sound; the locks were cargo-culted from a threading mindset that doesn’t apply.
What’s missing from all three
All three solutions are correct on this graph and all three hit the critical path. So my friend’s question — “which one is right?” — has an unsatisfying answer: they all are, for these four tasks. The more useful question is what they all leave out, because that’s what separates a demo from production code.
Cycle detection. Feed any of the three a graph where 2 depends on 3 and 3 depends on 2, and watch what happens:
cyclic = {2: {3}, 3: {2}} # 2 waits for 3, 3 waits for 2
async def main():
# cap it so the notebook doesn't hang forever
await asyncio.wait_for(run_with_events(cyclic), timeout=1)
try:
asyncio.run(main())
except TimeoutError:
print("deadlocked: 2 waits for 3, 3 waits for 2, nobody ever starts")deadlocked: 2 waits for 3, 3 waits for 2, nobody ever startsIt hangs. Task 2 is parked on task 3’s event, task 3 is parked on task 2’s event, and neither will ever fire — notice that nothing even prints a “starting” line. The condition and memoized versions do the same thing in their own way — silent deadlock, or in the recursive case unbounded recursion. None of them notices the graph is impossible; they just wait forever. In production “forever” means a stuck worker, a leaked connection, an alert at 3am, and a long hunt for why nothing is making progress.
Other gaps: none limit concurrency (a thousand ready tasks all launch at once and you exhaust your connection pool); none handle a task failing cleanly (in the gather versions, a raised exception cancels nothing and the siblings keep running orphaned). These aren’t oversights you fix by adding more code to the hand-rolled versions. They’re a signal that the dependency graph itself wants a real data structure. Which the standard library has.
What real engineers actually reach for
Since Python 3.9 the standard library ships graphlib.TopologicalSorter. It does exactly the bookkeeping all three approaches were re-inventing by hand: hold a dependency graph, hand you the nodes whose dependencies are all satisfied, and — crucially — detect cycles up front instead of deadlocking on them.
from graphlib import TopologicalSorter, CycleError
# the happy path: a linear-ish order that respects dependencies
ts = TopologicalSorter(tasks)
print("a valid order:", list(ts.static_order()))
# the cycle: caught immediately, with the offending nodes
try:
TopologicalSorter({1: {2}, 2: {1}}).prepare()
except CycleError as err:
print("CycleError:", err.args[0], err.args[1])a valid order: [1, 2, 3, 4]
CycleError: nodes are in a cycle [1, 2, 1]static_order() is the simple case — one thread, do them in order. But the docs describe a parallel mode built for exactly our problem, around four methods: prepare() finalizes the graph and raises CycleError if it’s cyclic; get_ready() returns all nodes whose dependencies are done; done(node) marks a node finished, unblocking its successors; and is_active() says whether any work remains. The documented example drives worker threads through queues. The same four methods drive an asyncio loop just as cleanly.
The other half of the modern answer is asyncio.TaskGroup, added in 3.11. It’s the structured-concurrency replacement for loose create_task + gather: tasks created inside an async with TaskGroup() block are owned by it, the block doesn’t exit until they all finish, and if any one of them raises, the group cancels the rest and propagates the error as an ExceptionGroup. No orphaned siblings, no lost references, no swallowed exceptions. Here’s that contract on its own:
async def flaky():
await asyncio.sleep(0.1)
raise ValueError("task 2 failed")
async def long_running():
try:
await asyncio.sleep(10)
except asyncio.CancelledError:
print("sibling was cancelled when its peer failed")
raise
async def main():
async with asyncio.TaskGroup() as tg:
tg.create_task(long_running())
tg.create_task(flaky())
try:
asyncio.run(main())
except* ValueError as eg:
print("caught:", [str(e) for e in eg.exceptions])sibling was cancelled when its peer failed
caught: ['task 2 failed']The sibling is cancelled the moment its peer fails, and the error surfaces through except* instead of vanishing. That’s the behavior all three hand-rolled versions lacked.
Put the two together and the scheduler is short, and it does everything the three approaches didn’t:
async def run_dag(graph, do_work, limit=None):
ts = TopologicalSorter(graph)
ts.prepare() # CycleError up front, no deadlock
sem = asyncio.Semaphore(limit) if limit else None
pending = {} # asyncio.Task -> node
async def worker(node):
if sem:
async with sem: # cap concurrency
return await do_work(node)
return await do_work(node)
async with asyncio.TaskGroup() as tg: # structured: failures cancel siblings
while ts.is_active():
for node in ts.get_ready(): # everything newly unblocked
pending[tg.create_task(worker(node))] = node
done, _ = await asyncio.wait(
pending, return_when=asyncio.FIRST_COMPLETED)
for finished in done:
ts.done(pending.pop(finished)) # unblock its successors
finished.result() # re-raise here if it failed
t0 = time.perf_counter()
asyncio.run(run_dag(tasks, handle))
print(f"graphlib + TaskGroup: {time.perf_counter() - t0:.2f}s") task 1 starting at 0.00s
task 1 done at 1.00s
task 2 starting at 1.00s
task 3 starting at 1.00s
task 2 done at 2.01s
task 3 done at 2.01s
task 4 starting at 2.01s
task 4 done at 3.01s
graphlib + TaskGroup: 3.01sThree seconds, same critical path as the hand-rolled versions — but now cycles raise instead of hang, a limit= caps how many tasks run at once, and a failure cancels the rest and propagates. The loop is the documented graphlib pattern, with asyncio.wait(..., FIRST_COMPLETED) standing in for the worker queue: dispatch everything ready, wait for the first completion, mark it done to unblock its successors, dispatch again. ts.is_active() keeps the loop alive exactly as long as there’s progress to make.
The concurrency cap is worth dwelling on, because it’s the gap that bites hardest in production. asyncio.Semaphore(n) lets at most n coroutines past async with at a time; the rest park until a slot frees. Without it, a graph with a thousand independent leaves opens a thousand sockets at once and your database refuses the connections. This is the real, correct use of an asyncio sync primitive — coordinating access across coroutines around a genuine await — as opposed to the no-op locks in approach 3. Same class of tool, opposite outcome, and the difference is entirely whether there’s an await inside the critical section.
leaves = {n: set() for n in range(8)} # 8 independent tasks, all ready at once
async def main():
peak = concurrent = 0
async def tracked(node):
nonlocal peak, concurrent
concurrent += 1; peak = max(peak, concurrent)
await asyncio.sleep(0.1)
concurrent -= 1
await run_dag(leaves, tracked, limit=3)
return peak
print("peak concurrency with limit=3:", asyncio.run(main()))peak concurrency with limit=3: 3The cap holds at three no matter how many tasks are ready. That one keyword argument is the difference between a scheduler that’s polite to its downstream services and one that knocks them over.
Where this shows up for real
The four-node graph is a toy, but the shape is everywhere once you start looking. A CI pipeline: lint and type-check can run together, tests wait for the build, deploy waits for tests. A data pipeline: extract from three sources in parallel, join them, then write — which is the entire premise of tools like Airflow, Dagster, and Prefect, all of which are, at their core, a DAG plus a scheduler. A build system: Make, Bazel, and friends are dependency graphs with caching bolted on. Even a single web request fanning out to a few backend services and combining the results is this same problem in miniature.
The lesson the three approaches teach, taken together, is that the hard part was never the asyncio. It was modeling the dependencies. Once the graph is a real object that knows how to detect cycles and tell you what’s runnable, the async part collapses into a dozen lines. My friend’s instinct to hand-roll it was the right way to understand the problem — you should write the Event version once, by hand, to feel how await and set line up with the edges of the graph. But the version that goes to production is the one that leans on graphlib for the bookkeeping and TaskGroup for the lifecycle, because those two have already thought about the cycles, the failures, and the cancellation that a demo gets to ignore.
The shape of it
Pulling the whole thing together. asyncio is one thread running an event loop that drives coroutines by .send(), parking each at its await points and handing the actual waiting to the OS. create_task turns a coroutine into a Task the loop runs concurrently; a Future is the placeholder it resolves. On top of that, scheduling a dependency graph is just “run each node when its predecessors are done” — which you can express with raw Events, a Condition, or memoized tasks, and all three are correct on a clean graph. What they miss is everything that isn’t clean: cycles, failures, unbounded concurrency. The standard library already solved the graph bookkeeping (graphlib.TopologicalSorter) and the task lifecycle (asyncio.TaskGroup), and the two compose into a scheduler that’s both shorter and more correct than any of the hand-rolled versions.
And the one idea to carry out of here, because it’s the thing people get wrong coming from threads: in asyncio, code between two awaits is already atomic. A Lock isn’t for protecting a dict — the single-threaded loop does that for free. It’s for holding a resource across an await, when you’re parked and don’t want anyone else walking into the same section. Get that distinction right and most of asyncio stops being mysterious. The rest is just a graph.